
i would love to see what happens if we let image embeddings have the kind of representational capacity that we allow for text embeddings (>=4096), dont even need to make model dim 4096, could just do a projection + attention pooling at the end

those experiments that show how a bunch of people's guesses of gumballs in a jar, the average converges upon the true value. I wonder how much that applies for non-quantitative things, like ideas etc. I also wonder if numerous LLM outputs could emulate this effect
one of the most interesting problems in generative AI right now is control, funneling randomness into useful things. At the same time applying many conditions simultaneously can lead to OOD or very narrow or distributions without many training examples that fall under it
some models seem to be significantly more pruneable than others. it seems to be relatively consistent across different sizes too. my guess would be that a lot of these models could benefit from just training longer and priortizing FLOPs for number of seen tokens over model size https://arxiv.org/abs/2403.17887
rotating frozen layers when attempting to fuse models together, or for training in general
https://twitter.com/Rui45898440/status/1772996453557997924
wonder if there is analogies to coordinate ascent or gibbs sampling? fixing one part and letting it be the condition for the optimization of the other

on variational inference/ELBO for the millionth time and noted that the mean field approximation methods can't capture covariance between dimensions really. wondering if something like VCReg could help by ensuring covaraince can be mostly ignored?
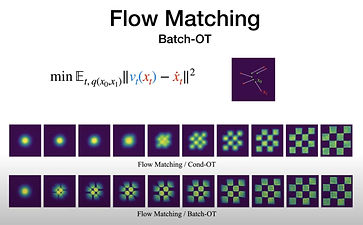
batch-OT is a fascinating idea
One thing I've wanted to do for a long time is take a large number of LoRAs or similar, give each a learnable coefficient for each layer that can be trained via backpropagation, finding optimal mixing strategies.
like Sakana evolution but with backprop
I think this goes to show skip connections can be useful, invariant to architecture specifics or modality you’re fitting to.
https://twitter.com/MatPagliardini/status/1771168258856501564
thinking self momentum distillation works because the the targets and weights can't change fast/concerted enough to collapse to the trivial solution. EMA can smooth out noisy weight updates and help late convergence. A latent loss removes the constraint of needing to have hidden states that can be mapped back to the observed states, allowing for more flexibility and possibly abstraction in how they're organized.
Probably obvious to most, but I've had sort of the slow-burn revelation over the past few months that I think just about all data that matters is synthesized from noise one way or another.
this is the second instance now ive seen of weak attention to the condition, like this https://arxiv.org/abs/2403.06764

Sort of related, I’ve long felt that we should be able to train many independent building blocks of models, then possibly some fuser layers between them. Way too many people spending big bucks on making nearly the same LLM
Can we "microdose" additional complexity for networks to generalize to more complex functions by sparsely adding tanh or sin functions as an alternative to MLP gates?
inspired by NeuralRedShift paper
https://twitter.com/Ethan_smith_20/status/1770002754812907603
I like to think of diffusion models as decomposed series of gaussians kind of in contrast to mixtures of gaussians
it's interesting how there's a lot of power in the methods of self-supervised learning, JEPA, consistency models, which all share operating at the brink of an objective that could collapse into the model producing same output for all inputs.

m realizing something human raters aren't really tested on is diversity of output. increasingly important with distillation methods. you can see that the quality is good, prompt adherence is respected, but I dont think they test to show if all outputs look similar
I think this is one of the most distilled ways to visualized how probability distributions reflect information
Someone left a comment on a Sora video something like “okay cool but why don’t you use ai to cure cancer or fix global warming” and that’s kinda stuck with me lately
I know work there is being done but it does feel weird that some of the more noble causes aren’t getting anywhere close to the same kind of funding
Might be related to this? https://arxiv.org/abs/2202.00666 Generated sequences are lower entropy than human. Paper claims human speech trades off between low/high entropy to convey information vs maintain understandability. Could imagine the stagnation from finding a cozy minima.
All things are hallucinations, but some hallucinations are useful
Diffusion could make a strong approach for text generation for the same reason MUSE and MaskGIT are strong approaches to image generation
MJ's overfitting is actually learning novel view synthesis
https://twitter.com/Ethan_smith_20/status/1767326699501342969
any merit in first training with far smaller batch sizes, seeing how far you can converge, and then raising the batch size from there?
most learned invariant representations are missed opportunities to learn equivariant representations. https://arxiv.org/abs/2403.00504
On KANS:
I think people are seeing improved accuracy and thinking MLPv2! Naturally more complex activations functions let you fit more complex functions but this isn’t inherently a desirable property in networks we want to generalize. https://arxiv.org/abs/2403.02241
I imagine this is appealing for NERFs and other similar cases where we overfit on purpose
it is: https://twitter.com/matte_ce/status/1786106325178503631
i think the underlying piece in DoRA is that maybe we should be tuning full matrices in the same manner. one of the karras diffusion papers found well-sized benefit with weight normalization that id have to guess is not specific to unet diffusion models https://arxiv.org/abs/2312.02696
i think there is a missing equivalent of "hard negatives" for text2image models. a lot of the captions on DrawBench are flat out unlikely or near impossible scenarios that divert expectations, and i don't feel like typical supervised training will fill that gap alone
Close string matches to these tricky prompts I feel like are much more likely to occur in in the wild datasets as typos or other incorrect text, so it just gets ignored
let's reflect on some conservative upper bounds at what you could store in a 4096 dim fp16 embedding - 4096 tokens at vocab size of 65,536 - 2/3 of the RGB channels of a 64x64 image - 32,768 tokens at 8,192 vocab size (thinking of VQGAN) - this jpeg image
something i'd be really interested to see about SD3 is whether the MM-DiT method actually confers the benefit or just allocating more parameters to handle text embeddings that are tuned to an image generation objective is the cause
On multiple token prediction paper:
it was only briefly touched upon, but is it correct that multi-token prediction is only valid in the case of greedy decoding? also IMHO it seems like it'd make more sense and parameter efficient to have 1 shared head but then 1-2 branching transformer layers for each token.
i wonder if some improved performance could be explained by sort of indirectly increasing batch size? you now have N x seq_len predictions coming out of the model, sort of increasing the number of problems seen in one forward pass
this possibly supports this thought. training at 4x but finetuning and inferencing at 1x tokens shows improved performance

any literature on diffusion being a means of avoiding error accumulation in recurrent functions? By nature it seems like its always pointing back towards the data manifold, having some self correcting properties, however i dont think this would necessarily solve exposure bias
its pretty universal for LLMs to have high cos sim between layers and steady increasing norm. knowing this tends to be the case, can we exploit this prior when we train/init? i.e. train small LM, then duplicate/init larger LM with its weights
following: https://arxiv.org/abs/2404.06773 shows 1. causal masking for unexpected tasks like image encoding can increase expressivity suggested by attn matrix rank and improved performance 2. gradually switching from bidirectional to full causal over course of training improves perf
something that chronically has driven me mad is trying to evaluate granular differences of generative ai methods when so much of it is subjective, many benchmarks can be poor or biased proxies, and in human evaluation it could literally be the difference of a lucky seed
FID is okay, but have seen some work that points out failure cases. CLIP score can give poor estimates, we should probably be using ensembles or something. Aesthetic scoring can be somewhat subjective but you hope it represents some kind of mean preference
this paper provides a related explanation for this phenomenon https://arxiv.org/abs/2106.03216 memorization/lack of editability-generalization can be a culprit of sparse data points rather than overfitting. kind of end up with islands of lone modes without much to interpolate with.